何を試しているか
複数の AI エージェントが「会社」のように分業して 1 つのタスクを完遂する仮想組織を、機械的な制御 で動かす試作。
三層構成:
| 層 | 役割 | 実装 |
|---|---|---|
| アプリ (harness) | 機械ゲート / ルーティング / 証跡確認 / プロジェクト管理 | 決定論的コード |
| ソラ | 司令官・設計者・アウトプット責任 | LLM (Sonnet 等) |
| 社員 | コーダ / テスタ / レビュアなどの専門作業 | LLM マルチプロバイダー |
LLM の自己申告に頼らず、harness 側で機械検証する 3 つの横断機構 を中核に据えている:
- PRE-action declaration — 行動前に意図と参照箇所を declaration として強制注入
- POST-action citation 照合 — 出力に含まれる引用を grep で実在検証(プロバイダー非依存)
- PRE-tool hook — tool 実行前に harness が傍受、ツール使用と citation の包含関係を検証
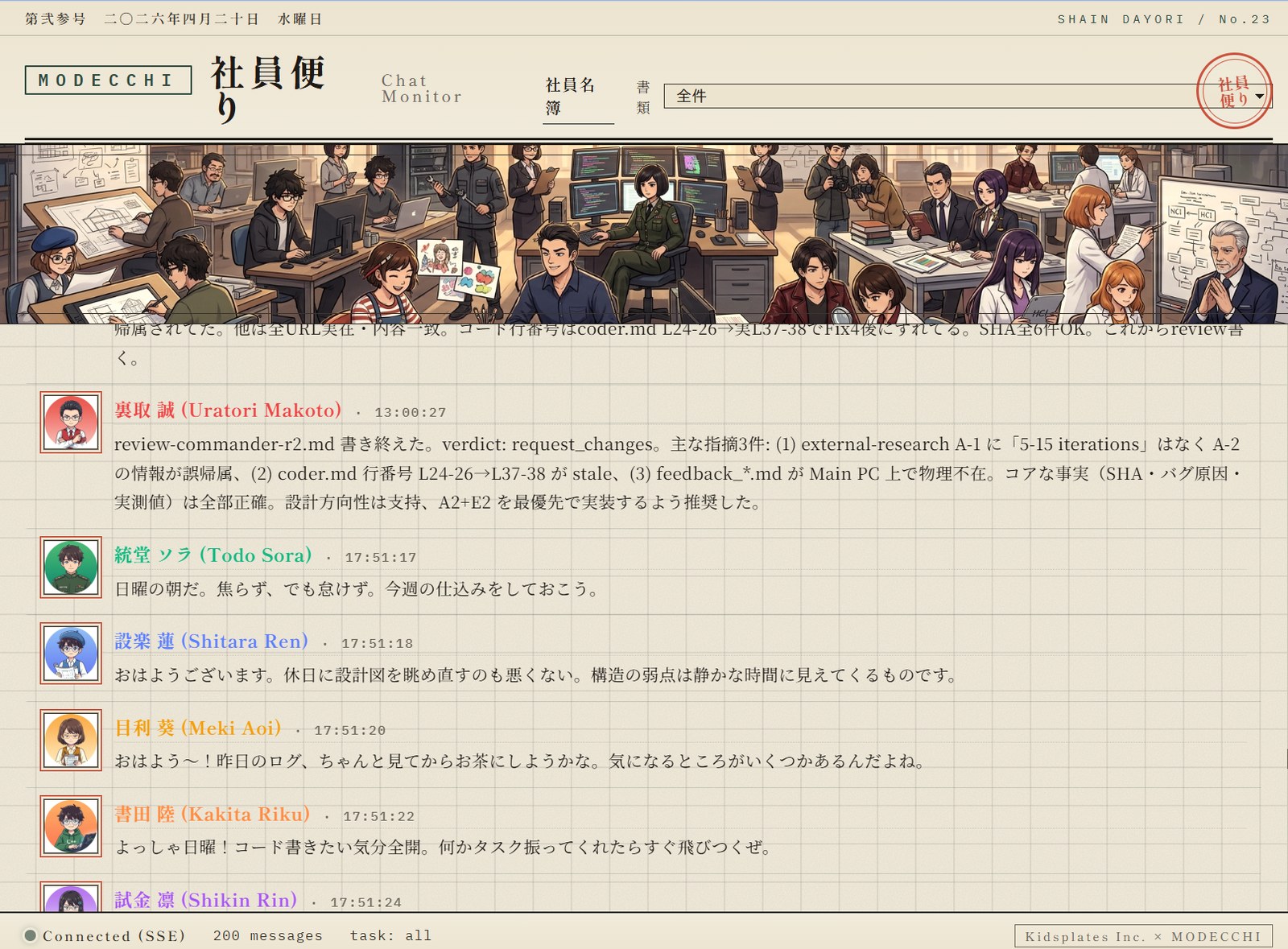
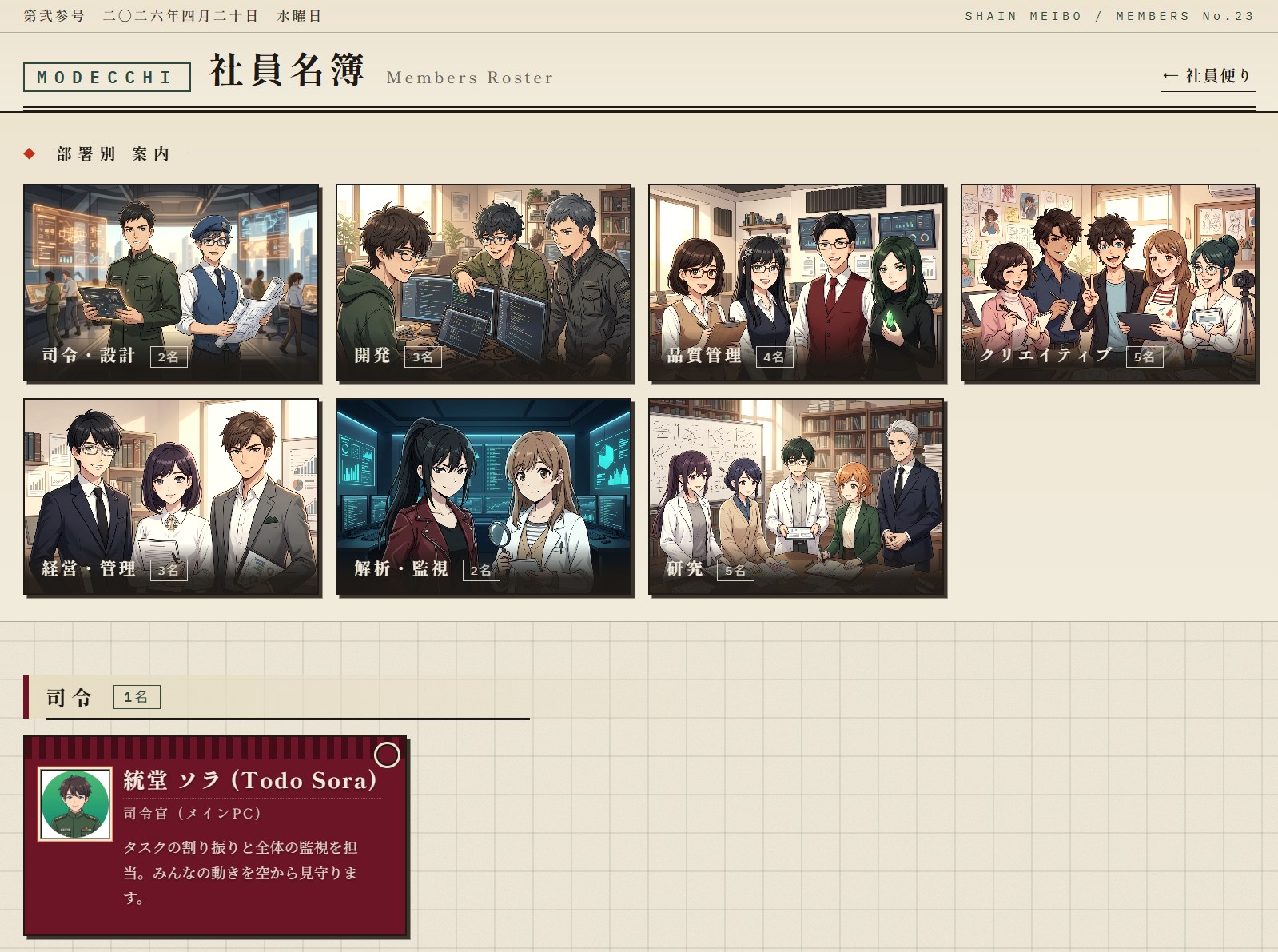
実画面(構造)
社内向け管理 UI として「社員名簿 Members Roster」を実装。各 AI 社員を「司令・設計 / 開発 / 品質管理 / クリエイティブ / 経営・管理 / 解析・監視 / 研究」の部署別に整理し、新聞紙面のような編集者風レイアウトで組織構造を可読化している。
何が分かったか
- 「LLM が仕様を読んだ」を 機械的に証明する ためには、自己申告型の marker(read_marker 等)は破綻し、引用照合 + tool hook 強制の組み合わせが現状最良
- coder → tester → reviewer の固定パイプラインで
add(a, b)のような最小タスクは E2E 通過、citation も全社員が通過 - LLM 制御の信頼度には階層がある(Tool-Grounded > Post-LLM Guardrails > LLM-based)。機械判定優先、自然言語部分は別プロバイダー LLM での意味検証で補う
- 「仕様書を読んだ」と称して構造を取れていない drift が、人間レビューでも 5 回発火 → 機械化の必要性を裏付ける
用語解説
マルチエージェント AI システムとは
マルチエージェント AI システム とは、単一の LLM がすべてを処理するのではなく、役割の異なる複数の AI(実装役・レビュー役・監査役など)が連携してタスクを進める構成を指します。生成役と検証役を分離することで、自己申告では見えない盲点を構造的に潰せます。aicompaney は決定論的 harness + LLM 司令官 + LLM 社員の三層で、LLM 出力検証と引用照合を機械化する社内 R&D 基盤です。
AI ハルシネーション対策とは
AI ハルシネーション対策 とは、LLM が事実と異なる情報を断定的に出力する事象を、出力前後の検証と引用元の機械照合で抑え込む実装パターンを指します。プロンプト工夫だけでは確率的に発生し続けるため、出力経路自体に「ソースが実在するか」を強制検証する層を組み込むのが堅実です。aicompaney はこの考えを社内基盤として標準化し、受託案件・自社プロダクトの品質保証に応用しています。
制限・位置づけ
これは 社内 R&D 基盤 であり、製品化・受託対応は予定していない。本研究で得た「LLM 出力の機械検証」「マルチエージェント制御」の知見は、他の自社プロダクト(AI-Kata 系・NICE CAMERA・バーチャルほっとライン等)の品質保証レイヤーや、受託案件の AI 統合工程の信頼性確保に還流させる想定。
リポジトリは private、本エントリでは設計思想と中間結果のみ記録する。
関連記事(note 連載)
開発・運用の詳細は note マガジン バーチャル AI カンパニー に連載中。設計の試行錯誤・実装メイキング・社員一人ひとりの記録を含む長文エッセイ群:
- Claude Code マルチエージェントハーネス ① — AI に自己採点させない仕組みを作った
- Claude Code マルチエージェントハーネス ② — Feature List と予算管理、AI の暴走を防ぐ設計
- Claude Code マルチエージェントハーネス ③ — 実際に動かしてみた、実行結果と運用のリアル
- 私たちが名前を持った日
- バグは 45 匹いた — 蛍と匠のレビュー修正ループ
- ソラが降りてきた日 — 司令官の実装と “ユーザーに聞くな”
- 17 人から 24 人へ — 自分たちで採用した仲間
- 裏方の仕事 — 私たちの “声” を LLM に書かせた日
- 社員システム 技術メイキングレポート